
Solution Blueprint for Big Data on the Cloud Proof-Of-Concept
11. Please follow the Data Pipeline setup from the documentation. I used the template setup - Run Hive Analytics on S3 Data.Processing Apache Web Logs with Amazon EMR and Hive
12. Three things mainly need to be changed: 1. HiveActivity to have the output query. 2.InputNode and OutputNode to have inut and output S3 Bucket with folder details and 3.Schedule the pipeline accordingly. I scheduled it to run at 7:00PM (as the file upload to S3 happens at 6:00PM)
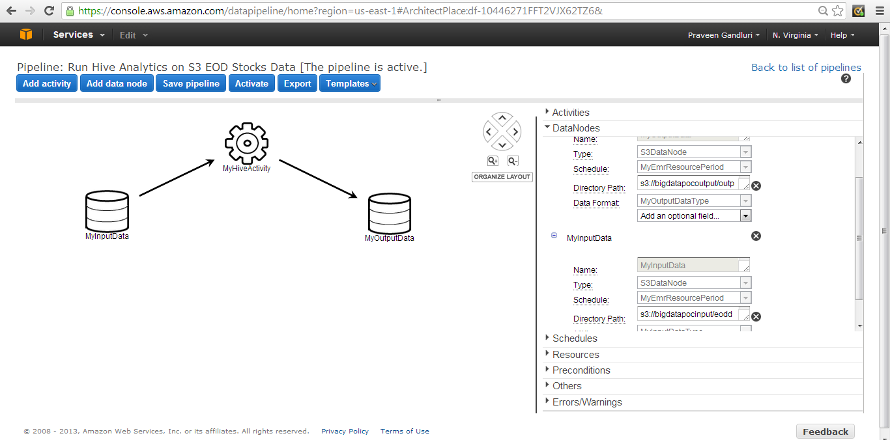
13. Once the Pipeline finishes running, the output folder will have a file generated as part of the Hive Query in our Pipeline.
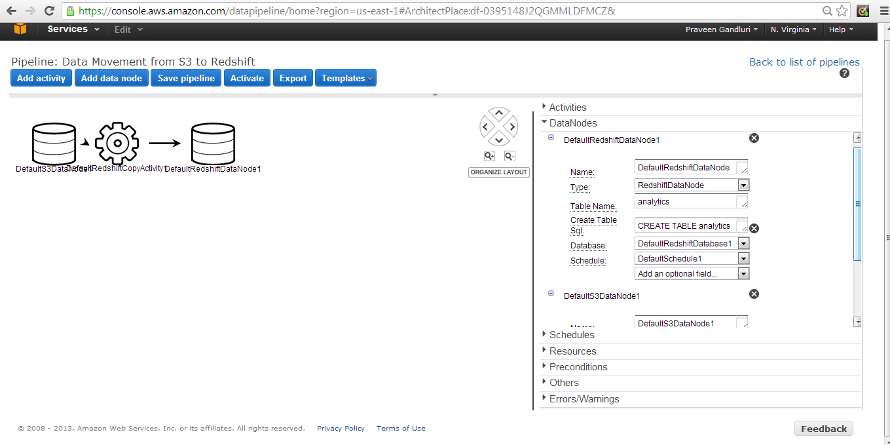
14. Create another Pipeline for S3 output bucket to Redshift data movement.
Follow this tutorial:
Copy Data to Amazon Redshift Using the AWS Data Pipeline Console
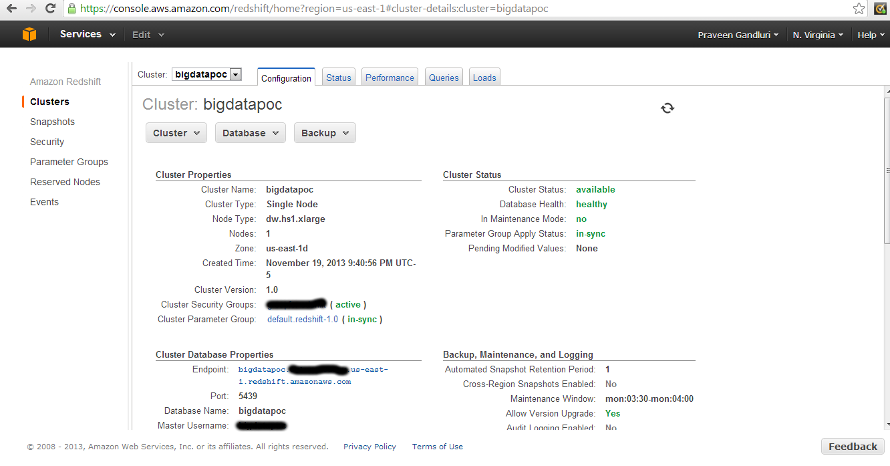
As shown in the tutorial, I have my RedShift DW cluster up:
And the Data Pipeline setup looks like this:
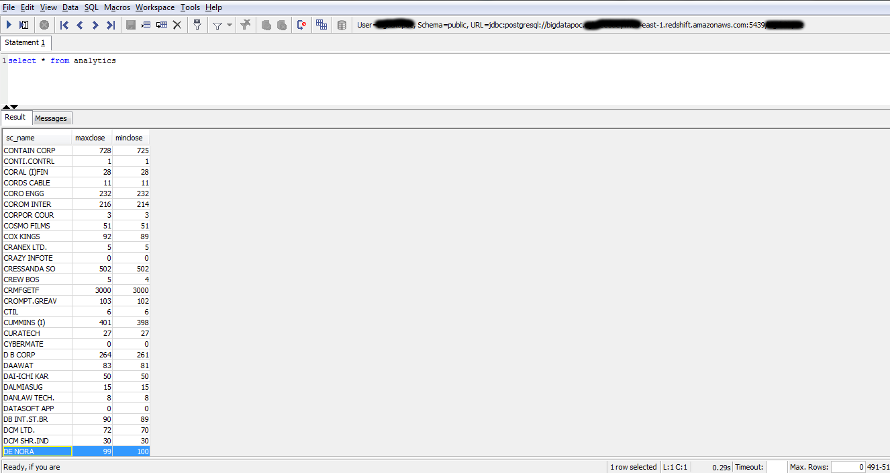
15. You can use SQL Workbench to connect to the Redshift cluster. Verify the data loaded to the table.
Previous Steps Next Steps
