
Solution Blueprint for Big Data on the Cloud Proof-Of-Concept
2013/Nov/10Nowadays the number one priority in CIOs' agenda is Big Data and Cloud adoption in the organizations. Many companies have started with Big Data Proof-Of-Concepts (POC), and you would hear a lot of lessons learnt in any conference you attend these days. Though there are many success stories, some POC attempts don't quite end up as expected and companies start to rethink their need for Big Data.
Two ways in which POCs fail are,
- When the Architecture for the POC is not robust enough, the time and efforts needed are very less initially, but productionalizing the solution is far more complicated and you might have to rebuild/rework everything again.
- On the contrary, if the Architecture is complicated, the time and effort as well as learning curve for the new tools will be a lot and you might realize that it could have been a lot more simpler.
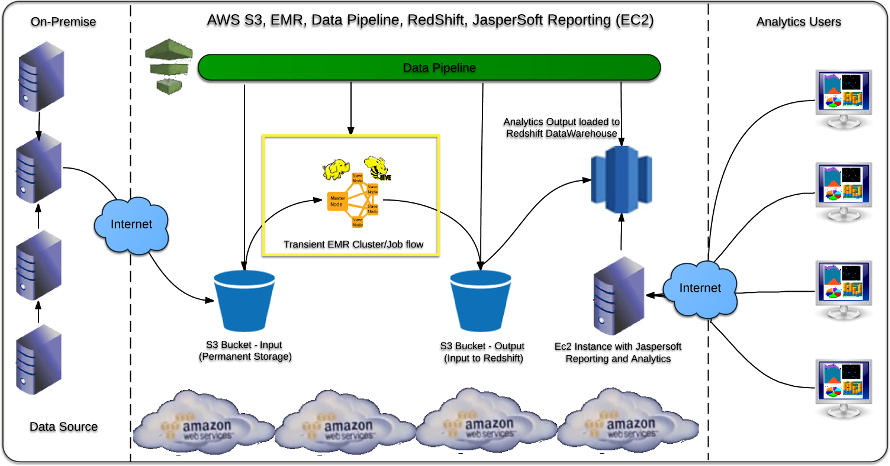
As part of the Solution blueprint, various tools and features available in Amazon Web Services (AWS) are used. Below is the list of the AWS Services used:
- AWS S3 – To store the input Data (for example, your log files used for Analytics), as well to store the analytics output.
- AWS Data Pipeline (to schedule the chain of data processing activities and data movement).
- AWS EMR Cluster/Job flow to run Hadoop MapReduce on S3 input data (specifically Hive in this case).
- AWS Redshift Data Warehouse to load analytics output and use for reporting.
- AWS EC2 instance with Jaspersoft Reporting and Analytics for AWS to connect to Redshift and serve reports/charts to the end users.
The main objective is to reduce the time to finish the POC (not months or weeks but in days or even less) and make it easy to Productionalize when ready.
Below is the architectural diagram:
Technical and process details of this demonstration:
- I am going to use the End-of-Day (EOD) stocks data from Bombay Stock Exchange (BSE) to demonstrate the architecture for the POC. Please take a look at my other website BSETrends to see what can be done with this data.
- Details about the input: BSE uploads a file comprising of the trade details for all the stocks after the end of each trading session. For simplicity, I am going to download and have it in a folder in my server, this is to simulate the Log files in an App Server. Every day a file will be present in on-premise server to upload to S3 at 06:00 PM.
- We will have a Java class in a JAR file (using AWS Java SDK) to take the EOD file from the input folder to load to a pre-defined S3 bucket. We will schedule this process through a cron job in Linux. This is comparable to using a log file from your App Server to fetch for analytics on regular interval (daily, for example).
- It's beneficial to have this S3 bucket as your permanent storage as well in future, after the completion of the POC. This can be used as input for various other services like DynamoDB or Redshift or another EMR cluster etc.
- Next, we will create a DataPipeline data flow to launch a transient EMR cluster to use our input S3 bucket and run a Hive query. This activity is also scheduled, so that every day once the file is uploaded to S3, EMR is launched, Hive query is run on all the EOD files that are in the bucket (the files get accumulated in the same bucket).
- The output of the Hive query is stored in another S3 bucket. As we are requesting a transient EMR cluster, the cluster will be terminated after the job finishes automatically. We can take different approaches later based on our need. Check out the details EMR Best practices .
- We will launch a Redshift Data warehouse service and create the final target table used for reporting.
- We will have another Data Pipeline with activity to load the S3 data to the Redshift table. This will be a merge process to the existing table.
- Finally we will launch an EC2 instance with Jaspersoft Reporting and Analytics for AWS and let the users run reports.
